SPTK で声質を変換する
音声信号処理のツールキット SPTK で声質を変換するテスト。
参考記事。
- SPTKの使い方 (10) ボコーダーで遊ぼう - 人工知能に関する断創録
以下の記事は上記ページで行われている作業をトレスしたもので、オリジナリティはありません。
自分の環境では働かない機能などがあり、ツールやコマンドは一部出入りがある。
使用したサンプル音源は GalateaTalk に付いてくる音声データ a10.raw。
RAW ファイルには再生に必要なヘッダー情報がなく、このままでは一般のオーディオプレーヤーで再生できないので、ヘッダー情報の付いた WAV ファイルに変換してきいてみる。
raw2wav は RAW 形式のファイルを WAV 形式に変える SPTK のコマンド。オプションでデータ型を指定しなければいけないが、わからないのでオプション無しでやってみた。
こんな音です。
まず音声からピッチを取り出して、テキストに落としてみる。
x2x はデータタイプの変換コマンド。オプションの +sf で short 型を float 型に変えてるらしいが、このへんの低水準のことはわからない(以下同様)。
pitch コマンドでピッチを抽出し、dmp コマンドでテキスト化している。
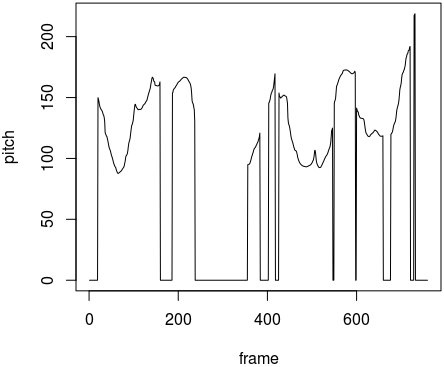
できた pitch.txt を R でグラフ化すると次のようになり、ピッチが抽出されているのがわかる。
次は音声の分解と再合成。
再合成された音声。
ほぼ元通りの音が再現されている。
ただし雑音が入った。以下の音声ファイルもすべて雑音入り。参考にした上記サイトでも同様のことが起きていて、原因は不明という。(自分が前にやった Open JTalk のテストでも雑音が入った。なにか共通の原因があると思う)
ピッチの抽出と再合成ができることがわかったので、ピッチを変えてみる。
sopr はスカラー演算の機能を提供するコマンド。-m オプションは掛け算。
ここでできた pitch.high.txt、pitch.low.txt と先につくった pitch.txt をあわせてグラフ化すると次のようになり、ピッチが high では2倍、low では2分の1になっているのが確認できる。
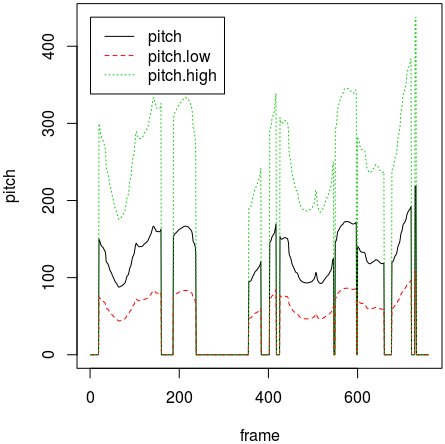
(訂正 - 上の図は誤りで、high と low のグラフが逆。縦軸の pitch はサンプリング周波数をHzで割った値とのことで、高い音ほど値が小さくなるという。- SPTKの使い方 (7) メルケプストラム分析合成)
実際にピッチを変えた音声をつくるコマンドは次の通り。
高い声。
低い声。
ピッチのかわりに速度を変えるコマンド。
速度を上げた声。
速度を遅くした声。
かすれた声をつくる。
結果のかすれ声。
ロボット声をつくる。
結果のロボット声。
子供の声と深い声。
子供の声。
深い声。
以上、コマンドの意味がわからないままやってみたが、パラメータを適当に変えれば何かが起こるということはわかった。
で、もう少し理解したいと思って検索したら、かなり古いものだが日本語のリファレンスがあった。
- SPTKリファレンスマニュアル - SPTKref-3.0.pdf
参考記事。
- SPTKの使い方 (10) ボコーダーで遊ぼう - 人工知能に関する断創録
以下の記事は上記ページで行われている作業をトレスしたもので、オリジナリティはありません。
自分の環境では働かない機能などがあり、ツールやコマンドは一部出入りがある。
使用したサンプル音源は GalateaTalk に付いてくる音声データ a10.raw。
RAW ファイルには再生に必要なヘッダー情報がなく、このままでは一般のオーディオプレーヤーで再生できないので、ヘッダー情報の付いた WAV ファイルに変換してきいてみる。
raw2wav a10.raw
raw2wav は RAW 形式のファイルを WAV 形式に変える SPTK のコマンド。オプションでデータ型を指定しなければいけないが、わからないのでオプション無しでやってみた。
こんな音です。
まず音声からピッチを取り出して、テキストに落としてみる。
x2x +sf a01.raw | pitch -a 1 > a01.pitch
dmp +f a01.pitch > pitch.txt
dmp +f a01.pitch > pitch.txt
x2x はデータタイプの変換コマンド。オプションの +sf で short 型を float 型に変えてるらしいが、このへんの低水準のことはわからない(以下同様)。
pitch コマンドでピッチを抽出し、dmp コマンドでテキスト化している。
できた pitch.txt を R でグラフ化すると次のようになり、ピッチが抽出されているのがわかる。
次は音声の分解と再合成。
x2x +sf < a01.raw | frame -l 400 -p 80 | window -l 400 -L 512 | mcep -l 512 -m 20 -a 0.42 > a01.mcep
excite -p 80 a01.pitch | mlsadf -m 20 -a 0.42 -p 80 a01.mcep| clip -y -32000 32000 | x2x +fs > a01.syn.raw
raw2wav a01.syn.raw
excite -p 80 a01.pitch | mlsadf -m 20 -a 0.42 -p 80 a01.mcep| clip -y -32000 32000 | x2x +fs > a01.syn.raw
raw2wav a01.syn.raw
再合成された音声。
ほぼ元通りの音が再現されている。
ただし雑音が入った。以下の音声ファイルもすべて雑音入り。参考にした上記サイトでも同様のことが起きていて、原因は不明という。(自分が前にやった Open JTalk のテストでも雑音が入った。なにか共通の原因があると思う)
ピッチの抽出と再合成ができることがわかったので、ピッチを変えてみる。
sopr -m 0.5 a01.pitch | dmp +f > pitch.high.txt
sopr -m 2 a01.pitch | dmp +f > pitch.low.txt
sopr -m 2 a01.pitch | dmp +f > pitch.low.txt
sopr はスカラー演算の機能を提供するコマンド。-m オプションは掛け算。
ここでできた pitch.high.txt、pitch.low.txt と先につくった pitch.txt をあわせてグラフ化すると次のようになり、ピッチが high では2倍、low では2分の1になっているのが確認できる。
(訂正 - 上の図は誤りで、high と low のグラフが逆。縦軸の pitch はサンプリング周波数をHzで割った値とのことで、高い音ほど値が小さくなるという。- SPTKの使い方 (7) メルケプストラム分析合成)
実際にピッチを変えた音声をつくるコマンドは次の通り。
sopr -m 0.5 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.42 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.high.raw
sopr -m 2 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.42 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.low.raw
sopr -m 2 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.42 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.low.raw
高い声。
低い声。
ピッチのかわりに速度を変えるコマンド。
excite -p 40 a01.pitch | mlsadf -m 20 -a 0.42 -p 40 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.fast.raw
excite -p 160 a01.pitch | mlsadf -m 20 -a 0.42 -p 160 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.slow.raw
excite -p 160 a01.pitch | mlsadf -m 20 -a 0.42 -p 160 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.slow.raw
速度を上げた声。
速度を遅くした声。
かすれた声をつくる。
sopr -m 0 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.42 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.hoarse.raw
結果のかすれ声。
ロボット声をつくる。
train -p 200 -l -1 | mlsadf -m 20 -a 0.42 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.robot.raw
結果のロボット声。
子供の声と深い声。
sopr -m 0.5 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.1 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.child.raw
sopr -m 2 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.6 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.deep.raw
sopr -m 2 a01.pitch | excite -p 80 | mlsadf -m 20 -a 0.6 -p 80 a01.mcep | clip -y -32000 32000 | x2x +fs > a01.deep.raw
子供の声。
深い声。
以上、コマンドの意味がわからないままやってみたが、パラメータを適当に変えれば何かが起こるということはわかった。
で、もう少し理解したいと思って検索したら、かなり古いものだが日本語のリファレンスがあった。
- SPTKリファレンスマニュアル - SPTKref-3.0.pdf