ditaa を日本語対応にする Awk スクリプト
ditaa はテキストで書いたグラフを画像に変換するツール。
- テキストで書いたグラフを画像化するツール ditaa
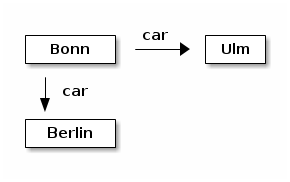
上のグラフのファイル名が graph.ascii であるとして、コマンドラインから
$ ditaa graph.ascii graph.png
とすると次のグラフができる。
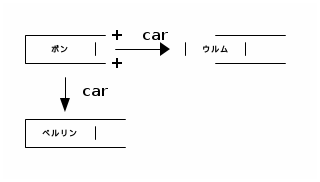
しかし次のように日本語が入っていると
このように壊れたグラフになってしまう。
これを避けるには、全角文字の後ろに半角スペースを付けてやるといい。
自動的に半角スペースを追加して ditaa で処理する Awk スクリプト jditaa を書いた。
これで次のようなグラフができる。
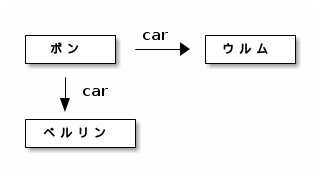
いちおう成功だが、日本語文字列の右が余分に空いてしまった。
上のテキストグラフを修正して、次のように日本語文字列の右側の半角スペースを1つ減らしてやると、バランスのいいグラフになる。
- テキストで書いたグラフを画像化するツール ditaa
+--------+ car +-----+
| Bonn | -----> | Ulm |
+--------+ +-----+
|
| car
v
+--------+
| Berlin |
+--------+
上のグラフのファイル名が graph.ascii であるとして、コマンドラインから
$ ditaa graph.ascii graph.png
とすると次のグラフができる。
しかし次のように日本語が入っていると
+--------+ car +--------+
| ボン | -----> | ウルム |
+--------+ +--------+
|
| car
v
+----------+
| ベルリン |
+----------+
このように壊れたグラフになってしまう。
これを避けるには、全角文字の後ろに半角スペースを付けてやるといい。
自動的に半角スペースを追加して ditaa で処理する Awk スクリプト jditaa を書いた。
# 使い方: awk -f jditaa <inputfile> <outputfile> [options]
# options は ditaa に渡すオプションをそのまま書く。
BEGIN {
infile = ARGV[1]
outfile = ARGV[2]
for (i = 3; i < ARGC; i++)
opts = opts " " ARGV[i]
while (getline < infile > 0) {
gsub(/[ぁ-んーァ-ン亜-龠、。]/, "& ")
print > "jditaa.temp"
}
system("ditaa jditaa.temp " outfile opts)
system("rm jditaa.temp")
}
これで次のようなグラフができる。
いちおう成功だが、日本語文字列の右が余分に空いてしまった。
上のテキストグラフを修正して、次のように日本語文字列の右側の半角スペースを1つ減らしてやると、バランスのいいグラフになる。
+-------+ car +-------+
| ボン | -----> | ウルム|
+-------+ +-------+
|
| car
v
+---------+
| ベルリン|
+---------+